Streaming Messages from Temporal Workers to SSE Clients

Temporal recently put out a wonderful demo of using Temporal to make prod-ready OpenAI agents, and I've seen many around asking a particular question about Temporal itself:
How do I stream responses from Temporal?
It's a natural question, given how often SSE responses are used with LLMs. There are a few ways to approach this
problem, but I will focus on a singular solution. I implemented my own Worker(s) -> SSE stream implementation about a
year ago to handle fan-out notifications, and will share it with you here.
I do not prescribe that this is the ideal solution, instead, this is meant to tease out some creative solutions from
you, the reader.
The Goals
We want to solve a few things:
- Make a Temporal workflow that can "stream" data as it works through a problem of some kind
- It should work across multiple workers
- It should allow more than one "receiver"
- Make a simple API
The Plan
We'll use a few components to achieve this:
- FastAPI for our API
- Temporal's Python SDK for our workers
- Redis, for pub-sub streaming
I mention in my Temporal talk that I prefer diagramming workflows as timelines; this time is no different! I always find it helpful to break down a Temporal flow as a timeline.
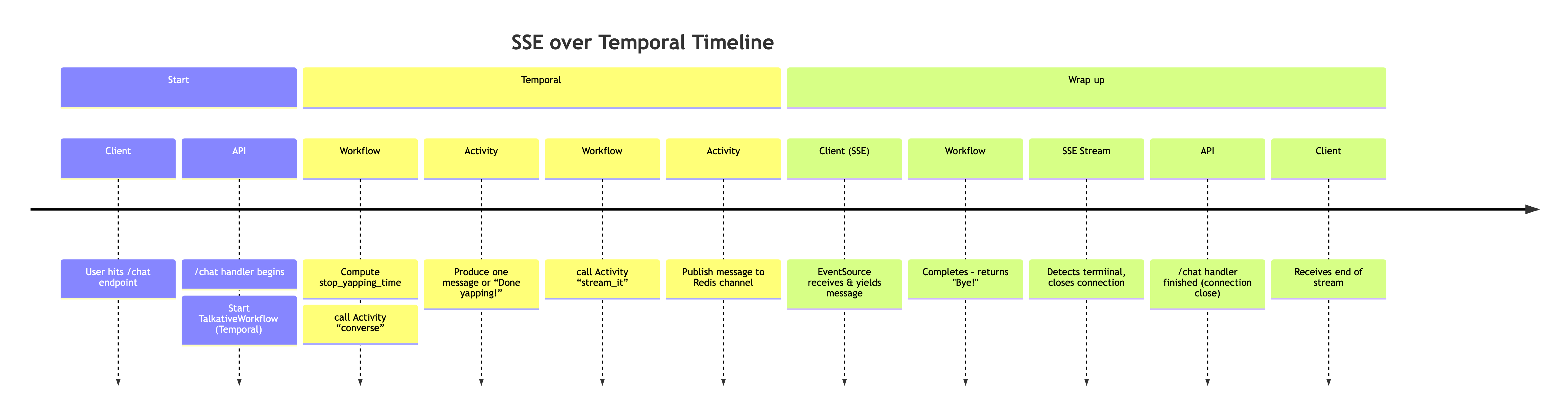
Let’s Build
To keep things relatively simple, we are not going to incorporate the OpenAI SDK in this demo, rather, we are going to simulate it. This workflow will be a contrived example of getting text back from a distributed workflow run, as the workflow is running. If you'd like more detail about using the OpenAI SDK with Temporal, please check out the blog I linked above.
Our LLM Simulation
LLMs are great at talking a LOT. To simulate that, we're going to use Faker with a generator. This gives our example here a clean abstraction and allows for anything with similar behavior (I.E., non-deterministic text generation) to be dropped right in. In fact, after checking out this post, head over to Dallas Young's example repo.
async def conversation_generator() -> AsyncGenerator[str, None]:
fake = Faker()
for _ in range(10):
await asyncio.sleep(1) # simulate a slow LLM
yield fake.sentence()
Nothing too surprising going on here, it's just a simple async generator that pops out random sentences from Faker.
The Activities
Stepping one level up the implementation layers, we examine our stream-capable activities:
class MyActivities:
def __init__(self, redis_client: Redis):
self.redis_client = redis_client
@activity.defn
async def stream_it(self, params: tuple[str, str]) -> None:
channel_id, message = params
await self.redis_client.publish(channel_id, message)
@activity.defn
async def converse(self, params: tuple[datetime, datetime]) -> str:
stop_after, now = params
if now < stop_after:
async for sentence in conversation_generator():
return sentence
return "Done yapping!"
First, we define this activity as a class with methods, instead of standalone functions, simply to share the Redis
client. If one so desired, one could have functions do this as well, perhaps with recreating the Redis client each time,
or putting the client in global scope. Personally, I don't like either of those solutions, so we have this class.
There are two activities here:
converse, the piece that actually gets sentences from our fake LLM- Note how the timing info is included in the params, and not a concern of the activity function itself. This is to
keep our activity from blowing
up Temporal's Python SDK sandbox behavior.
datetime.now(UTC)is considered non-deterministic, so instead we need to use workflow.now, which we invoke from our workflow scope, not our activity scope.
- Note how the timing info is included in the params, and not a concern of the activity function itself. This is to
keep our activity from blowing
up Temporal's Python SDK sandbox behavior.
stream_it, the piece that sends some data off to Redis PubSub
The Workflow
Next we look at the workflow that ties the activities together (another step up the layers)!
@workflow.defn
class TalkativeWorkflow:
"""A very talkative workflow!"""
@workflow.run
async def run(self, channel_id: str) -> str:
stop_yapping_time = workflow.now() + timedelta(seconds=15)
while True:
now = workflow.now()
result = await workflow.execute_activity(
"converse",
(stop_yapping_time, now),
start_to_close_timeout=timedelta(seconds=60),
)
await workflow.execute_activity(
"stream_it",
(channel_id, result),
start_to_close_timeout=timedelta(seconds=60),
)
if result == "Done yapping!":
break
return "Bye!"
This workflow enters a loop where it creates one "converse" and one "stream" activity per loop, until it receives a terminal message from the source of conversation. In this case, the terminal message is "Done yapping!"
It's important to point out, I am merely using a loop here as part of the LLM simulation. When interacting with a real LLM, or some other source of continuous text info, the program loop will likely be better defined.
The Worker
Workflows and activities are meaningless if we don't have a Worker, so we move up the layers once again and build one.
async def make_worker():
redis_client = Redis(host="redis", port=6379)
activities = MyActivities(redis_client)
client = await Client.connect("host.docker.internal:7233")
worker = Worker(
client,
task_queue="talkative-queue",
workflows=[TalkativeWorkflow],
activities=[activities.stream_it, activities.converse],
)
await worker.run()
if __name__ == "__main__":
asyncio.run(make_worker())
A more robust version of this may include a halt event of some kind, but I digress; this will work fine for our example.
The API
All this is well and good so far, but still meaningless without an actual interface! Time for an API!
app = FastAPI()
@app.get("/chat")
async def chat() -> EventSourceResponse:
# please don't instantiate your temporal/redis clients like this in real code!
client = await Client.connect("host.docker.internal:7233")
redis_client = Redis(host="redis", port=6379)
workflow_id = "talkative-workflow"
channel_id = "talkative-stream"
pubsub = redis_client.pubsub()
await pubsub.subscribe(channel_id)
await client.start_workflow(
"TalkativeWorkflow",
channel_id,
id=workflow_id,
task_queue="talkative-queue",
)
return EventSourceResponse(stream_handler(pubsub))
async def stream_handler(subscription: PubSub) -> AsyncGenerator[str, None]:
try:
while True:
message = await subscription.get_message()
if message and message["type"] == "message":
data = message["data"].decode("utf-8")
if data != "Done yapping!":
yield data
else:
break
finally:
await subscription.unsubscribe()
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
There's a bit to breakdown here:
EventSourceResponse, this is a helper from thesse-starlettelibrary that simplifies sending SSE conforming responses.stream_handler, something has to actually subscribe to those Redis PubSub channels; this is the mechanism that does it.- Note how it looks for the same terminal message that we described before.
Putting them All Together
We'll use docker (or podman) compose, so first we need to dockerize our worker and API:
# https://github.com/astral-sh/uv-docker-example/blob/main/Dockerfile
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim as base
WORKDIR /app
COPY uv.lock pyproject.toml ./
RUN --mount=type=cache,target=/root/.cache/uv \
uv sync --locked --no-install-project --no-dev
COPY . /app
RUN --mount=type=cache,target=/root/.cache/uv \
uv sync --locked --no-dev
ENV PATH="/app/.venv/bin:$PATH"
ENTRYPOINT []
FROM base AS api
CMD ["python", "main.py"]
FROM base AS worker
CMD ["python", "worker.py"]
Note that both units use the same Dockerfile. We build via their respective targets.
And now we need to define our compose stack:
services:
api:
build:
context: .
dockerfile: Dockerfile
target: api
ports:
- "8000:8000"
depends_on:
- redis
worker:
build:
context: .
dockerfile: Dockerfile
target: worker
depends_on:
- redis
redis:
image: redis
platform: linux/arm64/v8 # set this to the platform of your choice
ports:
- "6379:6379"
Let's Run this Thing!
Almost there... let's get a Temporal dev server running and then launch the compose stack
temporal server start-dev
docker compose up --build
Now that our stack is up, let's test this out!
curl -N http://localhost:8000/chat
...
data: Although well performance center human raise most.
data: Note direction how adult.
data: Sometimes weight destroy discuss.
data: Raise outside people culture.
We've got SSE streaming! Note the format here, the messages are prefixed with data:.
Quick Aside About the Timeout
Going back to the workflow, did you notice how I set a fifteen-second timeout for the example? There's a reason. Near
the end
of our artificial timeout, you probably saw this message: : ping - 2025-08-07 02:45:13.448444+00:00 or something
similar. An SSE event starting with : is a comment. Diving into the source for sse-starlette's EventSourceResponse
object, we see:
class EventSourceResponse(Response):
"""
Streaming response that sends data conforming to the SSE (Server-Sent Events) specification. """
DEFAULT_PING_INTERVAL = 15
...
async def _ping(self, send: Send) -> None:
"""Periodically send ping messages to keep the connection alive on proxies.
- frequenccy ca every 15 seconds. - Alternatively one can send periodically a comment line (one starting with a ':' character)"""
I wanted to bring attention to this in particular because I've seen folks try to "catch all" with PubSub messages. Instead, only aim to deal with known messages and discard the rest. Aka, ignore the comments!
Wrapping Up
And there you have it, streaming data from Temporal workers over Redis PubSub.
Hold Your Horses, Cowboy 🤠
Please don't just copy/paste this code into prod. There are particulars here you should keep in mind:
- Redis PubSub:
- Keep in mind that this is adding another "broker" to the system; that means extra cost, and extra complexity. Adding it was a "no-brainer" for my own architecture, as I was already using Redis for other purposes.
- This is NOT a durable delivery format, it is purely fire-n-forget. These messages evaporate into the ether after they've been sent. Make sure that aligns with your spec; if not, consider something more durable like Redis Streams.
- If you use this for an LLM, you may consider batching the responses, depending on the volume of users you expect. Keep in mind the network and memory model of how the API, Redis, and Temporal workers communicate with each other.
- Speaking of Redis, make sure you're using the async-compatible version of the client, and PubSub:
from redis.asyncio import Redisandfrom redis.asyncio.client import PubSub
- SSE:
- There are particulars to using SSE, especially across HTTP 1.1 - HTTP/2 boundaries. Please save yourself some heartache and read through MDN's SSE guide.
- API Design:
- If you have an endpoint that can return SSE content, consider adding
the Accept header to your contract.
What I mean is, if the user can ask for SSE from an endpoint, that endpoint should make that clear by saying it
will respect
Accept: text/event-streamheaders.
- If you have an endpoint that can return SSE content, consider adding
the Accept header to your contract.
What I mean is, if the user can ask for SSE from an endpoint, that endpoint should make that clear by saying it
will respect
Further Reading
- View the complete code sample for this blog here.
- Check out Temporal's agent demos!